Using Git Commits to Learn to Program Ruby on Rails
I've been actively working on a side project for the past several months and one of the people who has been helping out a bit around the edges wants to learn how to program Ruby on Rails. Since this, like everything I always do, is a distributed, remote effort, an in person teaching effort just doesn't work.
When they pushed back on the feature set I was making and said that it wouldn't work for them, I said "Well that's fine, tell me what you want". And they responded with a detailed set of Agile User Stories. I took a look at these and I realized that if I mapped them into Github issues (aka tickets) and then Github Pull Requests that this might be exactly the right tool to get this person past the learning hump.
Note: Just to be clear, it doesn't matter what the side project is. Yes it is live on the Internet but it is buggy as hell. And this is a major new feature. The whole point of this blog post is to talk about a new learning technique not "Scott's (current) Crazy Side Project".
Learning from Code Commits
The hard part with learning any new development framework is making the leap from "here's what I want" (the story) to "here's what to do to make that" (the code and tooling steps). Now if you use Github how we do, with a simple branch based development model, where 1 issue maps to 1 branch, this means that you can actually look at a user story and then see all the changes.
This is a weird enough learning concept that I'm going to illustrate this step by step.
Beginning With the Story
Let's start with the agile user story:
As a user, I want a currency system (ChangeCoins - CC) that is awarded to me for doing stuff.
From a Rails perspective, what this means, is that we need a data model, persistently stored to the database that tracks something else.
Continuing to the Issue
Let's look at the issue in question:
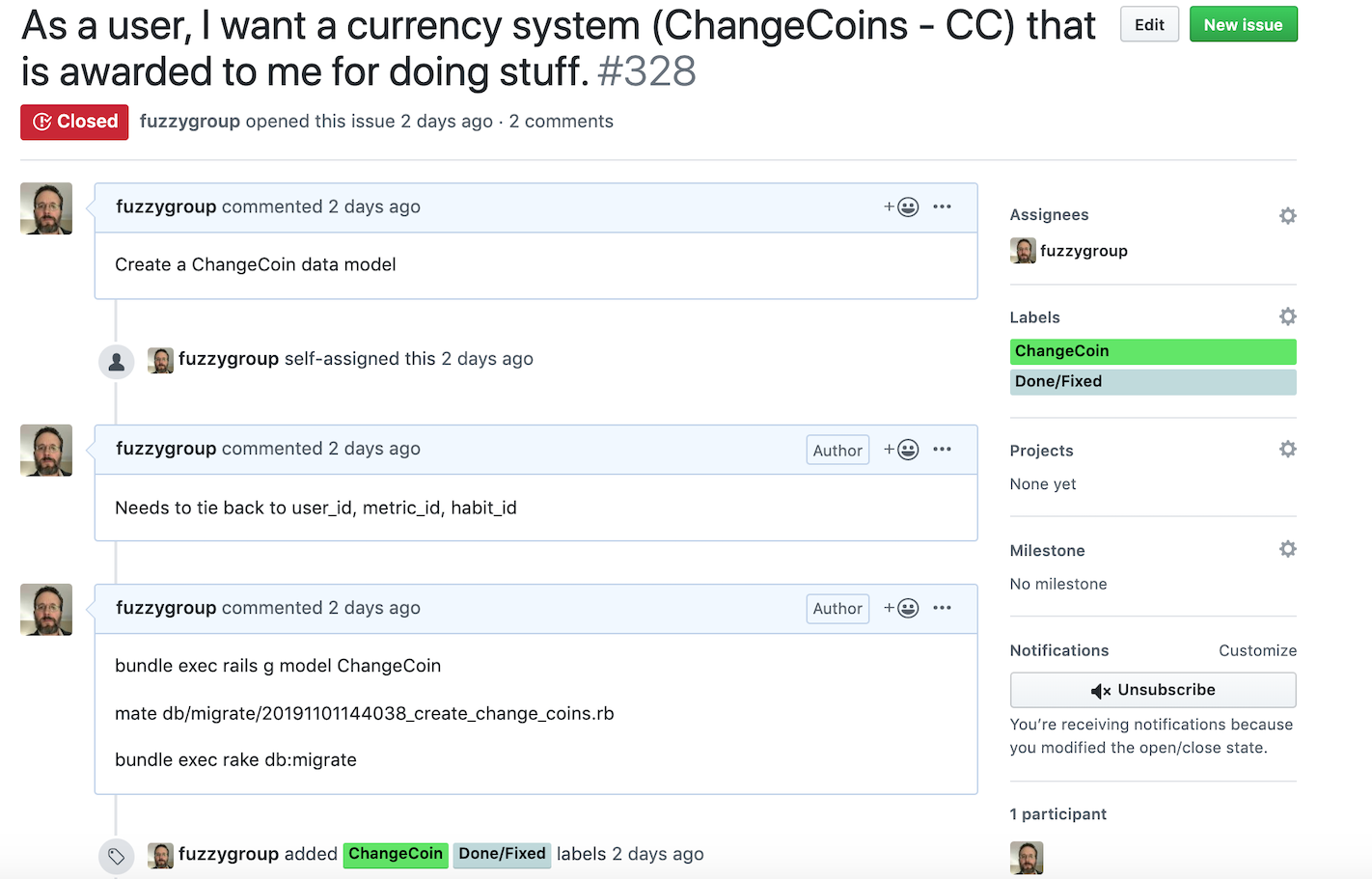
There are a few notes on the issue here:
- "Needs to tie back to user_id, metric_id, habit_id" - this indicates foreign key relationships back to other data models in the project
- "bundle exec **rails g model **ChangeCoin" - this is a Rails generator command which scaffolds up a new data model and all associated files
- "mate db/migrate/20191101144038_create_change_coins.rb" - this is just opening the migration (a migration is a set of DDL commands to create a table or change something in the database)
- "bundle exec rake db:migrate" - this executes the migration
A big reason for the notes on the issue is that if I don't put notes into the issue, how would you know that there are commands like:
- rail g model
- rake db:migrate
These commands don't exist in the pull request so they have to be manually documented.
Note: If you're going to use this approach then I strongly, strongly advise you to add a label to your issues so that all issues can be logically grouped together. Even though you think "Oh I'll just work on this one thing", something else will come up (I got 2 issues into Change Coins and then found 4 other bugs, each of which was its own issue).
The Branch
Now we need to turn to the Github branch and the pull request. A pull request is a set of changes that, for this project, represent what happened in the branch.
Let's start with the changed files in this branch:
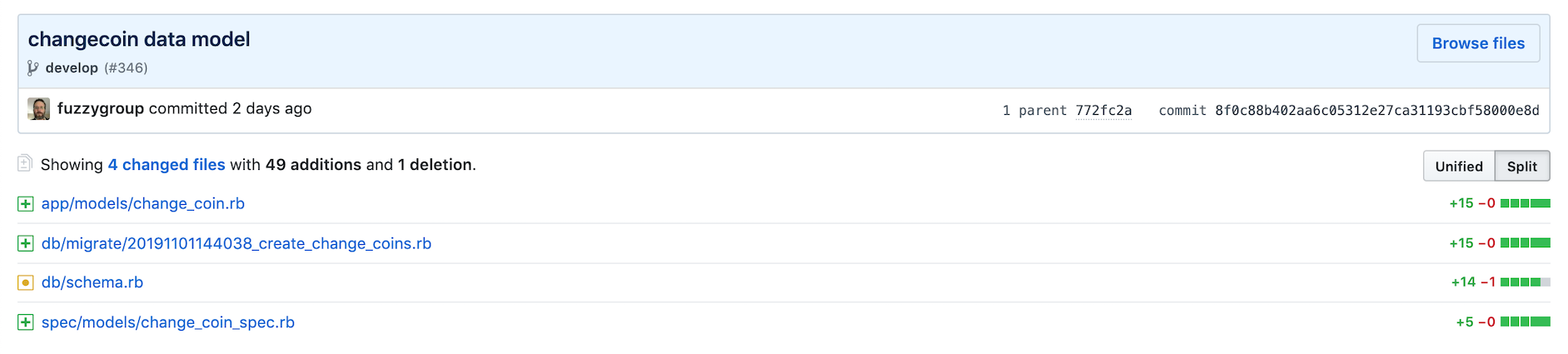
This shows that 4 files changed. Now of these four files, one was automatically generated by the system (schema.rb) and isn't ever touched by the user and the other (reward_spec.rb) is just a skeleton file at this point so neither of these files will be shown.
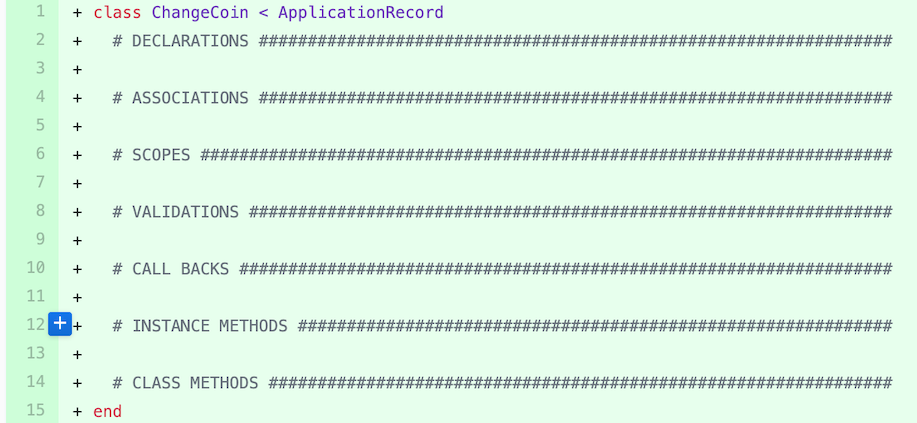
This is a Rails model file. The source code comments beginning with pound symbols organize the model and illustrate where required things should be placed. This isn't a Rails convention, this is a "Scott" convention as I find it helps me avoid making mistakes.
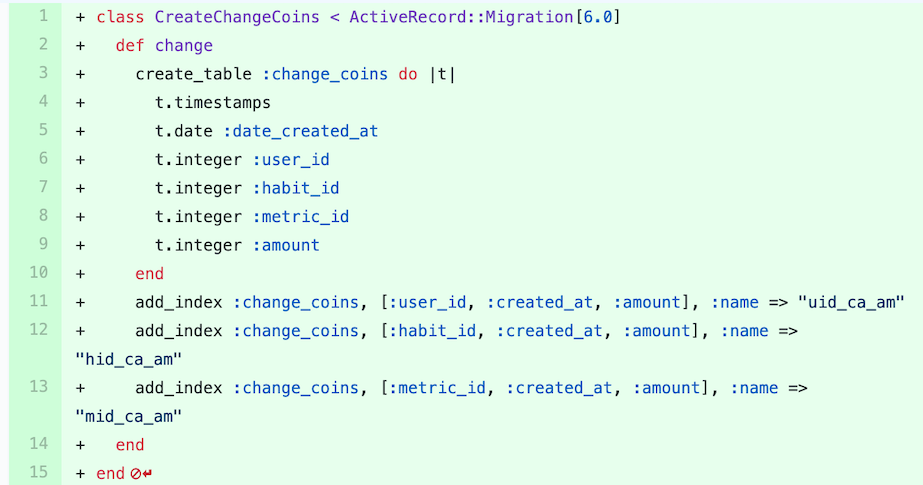
This is a Rails migration file. It lays out the data model for the entire table that stores the rewards for the user.
Conclusion
This isn't a perfect approach to learning, specifically:
- Issues need to map 1:1 to agile user stories
- Commands aren't captured by the git commit so you have to manually update the issue to capture them
- It is mildly challenging to go back into a closed issue and find the changes related to the pull request because the request doesn't automatically track to the issue number but instead to the git commit hash; this might be a problem with me and how I name the pull requests; tbd.
Even with these problems, I think there might be something interesting here. I'll keep you posted if any real learning occurs from this.