The Real Reason We Have Rake Tasks - Developers Make Mistakes

If you are a rails developer, you are likely aware of Rake tasks. Rake tasks provide a very easy way to write a command line task that ties into your overall system. And command line tools are really, really useful of course but I often think that Rake tasks were invented mainly as a way for developers to easily clean up errors they make.
Here's an example:
- I'm working on a system where I've heavily built in gamification in the form of earned badges in response to user metrics.
- I recently added the ability to import your RSS feed as a way of tracking word counts (one of the metrics is the words you write).
- Yesterday I triggered an RSS import for the first time and I discovered that, in one day, I earned 521 badges.
- Gulp.
Clearly something has gone awry – majorly awry. And the way that I tackle issues like this is, well, a rake task.
Sidebar: If you're a newbie Rails person, rake tasks live in the directory lib/tasks and they have a syntax like that shown below (they begin with namespace and then there are a series of task lines; if the task references environment then the entire Rails environment is available to the rake task otherwise it is just plain old Ruby and none of the Rails niceties).
My rake tasks are named two ways:
- functionally for what they do "spider_app_store"
- tied to the data object that needs cleanup i.e. "user_badge"
I have three tables in question:
- badges
- user_badges
- metrics
There is a callback on metrics that calls add_user_badges and it is an after_create callback. This routine takes the individual metric and passes it into the badge routine which has a rule which is dynamically evaluated. And then the output of that rule, if it succeeds, is the creation of a user_badge.
Let's start by looking at the metric in question:
select id, created_at, date_created_at, name, metric_type_id, user_id, habit_id, habit_type_id, int_val, url from metrics where id=1516\G
*************************** 1. row ***************************
id: 1516
created_at: 2009-12-14 00:00:00
date_created_at: 2009-12-14
name: word_count
metric_type_id: 1
user_id: 1
habit_id: 41
habit_type_id: 11
int_val: 107
url: https://fuzzyblog.io/recipes/main_course/2009/12/14/bacon-salisbury-steak.html
Somehow this event, way back in 2009, triggered a badge creation on 9/19:
![]()
So now we need to look at the data driving that badge to figure this out:
select * from user_badges where id=550\G
*************************** 1. row ***************************
id: 550
created_at: 2019-09-19 19:49:21.346148
updated_at: 2019-09-19 19:49:21.346148
date_created_at: NULL
user_id: 1
badge_id: 3
habit_id: 41
plan_id: 1
metric_id: 1516
custom_message: NULL
active: 1
What this shows us is that we have a disparity between the created_at date on the user_badge object and the metric. So the fix is actually pretty damn simple. Here's the creation code:
attributes = {
badge_id: badge.id,
metric_id: metric.id,
user_id: metric.user_id,
habit_id: metric.habit_id,
plan_id: metric.habit.plan_id,
active: true
}
user_badge = UserBadge.create(attributes)
and what it needs is this:
attributes = {
badge_id: badge.id,
metric_id: metric.id,
user_id: metric.user_id,
habit_id: metric.habit_id,
plan_id: metric.habit.plan_id,
created_at: metric.created_at,
date_created_at: metric.date_created_at,
active: true
}
user_badge = UserBadge.create(attributes)
Note: Are there better, cleaner ways to accomplish that? I'm sure but that isn't the issue at this stage in an MVP. At this stage we're going for clarity even if it isn't entirely DRY.
But this blog post was actually about rake tasks and here's where we come back to that. I have two options facing me:
- Delete the data and reload
- Fix the data
I personally really enjoy writing rake tasks and one of the reasons is that I've always found that errors that occur once tend to occur multiple times. And even i the exact error doesn't occur again, similar errors often do and then your one off rake task becomes something you can quickly and easily compose into an alternate fix routine.
Note: This is why I tend to name my rake tasks for the data object they operate on; it makes finding them trivial.
Here's the rake task to fix this bit of personal idiocy:
namespace :user_badge do
# bundle exec rake user_badge:fix_idiocy --trace
task :fix_idiocy => :environment do
user = User.where(username: 'fuzzygroup').first
user.user_badges.each do |user_badge|
attributes = {
created_at: user_badge.metric.created_at,
date_created_at: user_badge.metric.date_created_at
}
user_badge.update_attributes(attributes)
end
end
end
You'll notice that I have a bundle exec execution line there as a comment. Well, there's a reason for that. I've been doing Rails with large scale live systems now since 2007 and I've seen the amazing quantity of data specific errors that can happen when you're in a:
- poorly funded
- fast paced
- get the job done
type startup. Errors like these (getting the date wrong) tend to slip into even production systems and when a founder / CEO notices them in the wee hours of the night and you happen to be the on goal idiot, well, it is much easier to copy and paste in a commented out bundle exec execution line than it is to figure it out on the fly. This is even more true when the rake task takes some number of command line arguments.
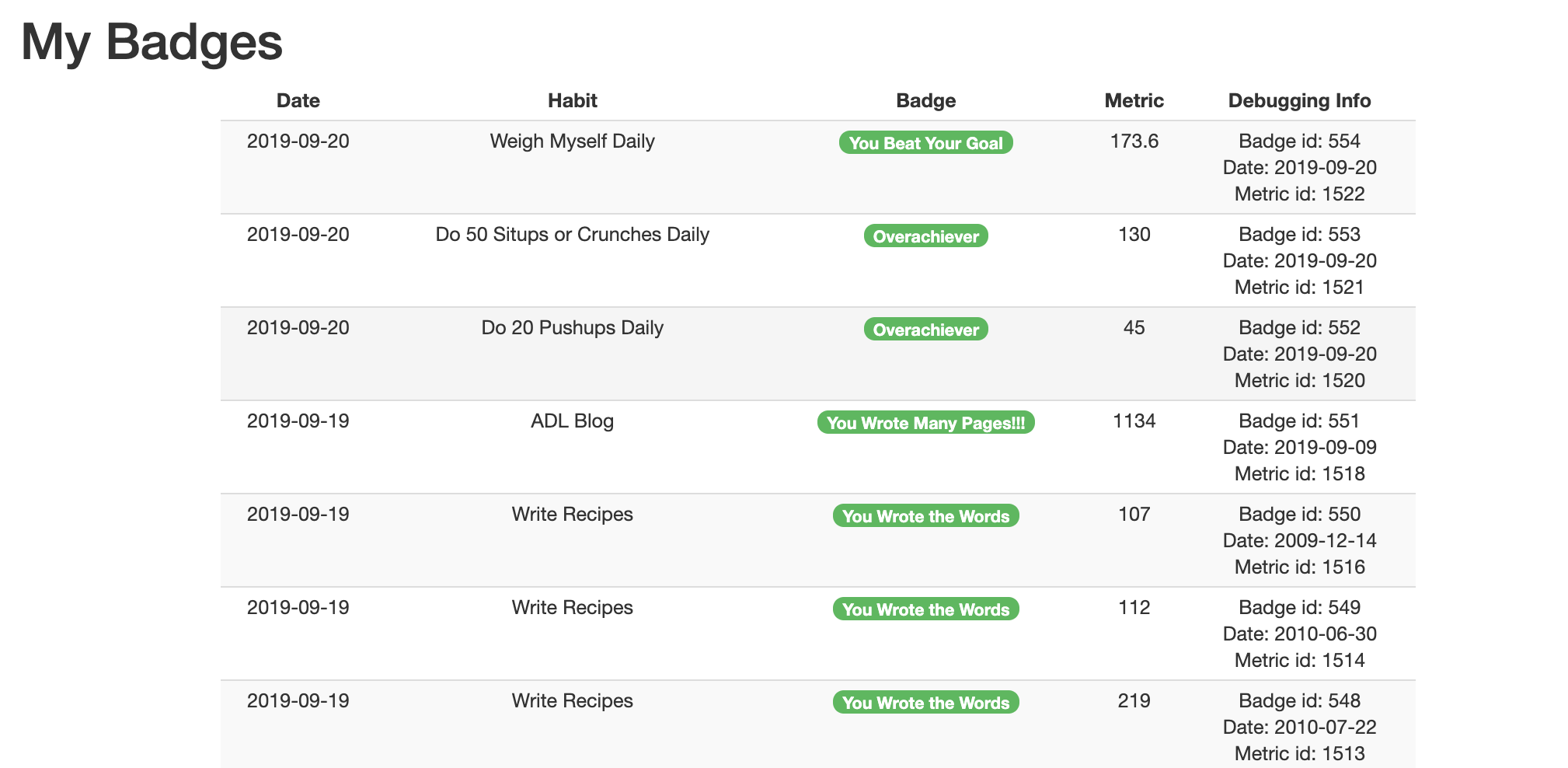
So I ran this and it seemed to work but the real proof is whether or not the result makes sense. Here's the look and feel before and after (focus on the habit column; you'll see that it goes from a succession of recipes to a more varied set of habits).
Before
After
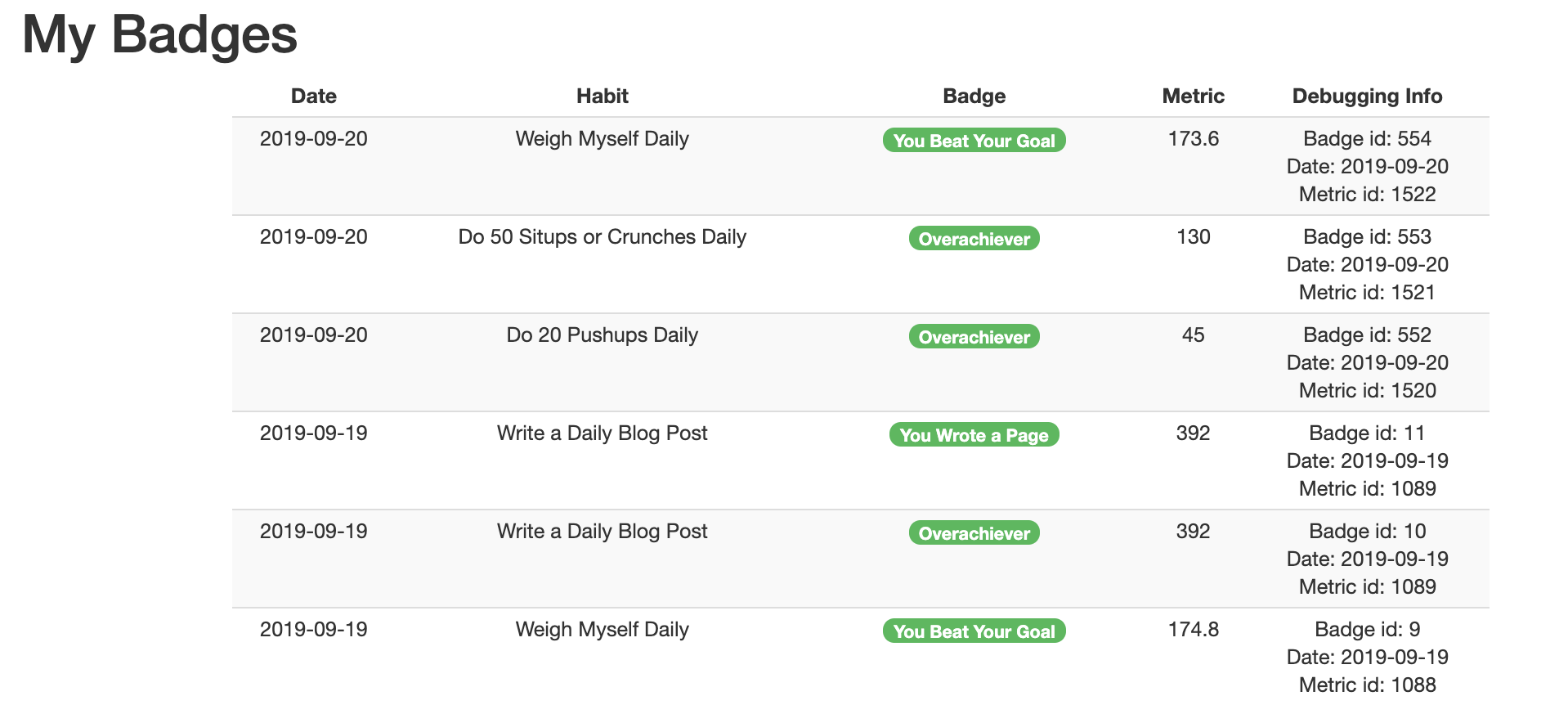
Conclusion
And there you have it – the real reason that rake tasks exist – developers make mistakes and rake tasks make fixing those mistakes really, really easy.