To Compress or Not to Compress - An S3 Question
I'm finally at what I refer to derisively as the "Turd Polishing" stage of a new SAAS application that I hope to roll out over the next month or so. I've validated the:
- the market
- the concept
- figured out how to get initial users over the OOBE (out of box experience)
and now I'm at the stage of looking at the underlying crawler / indexer and how it acquires data. Up to this stage I've been archiving daily crawl data to a flat directory on my hard disc and when I realized that I had over a million html archive files in a single directory, well, oops. So yesterday was devoted to moving them into date named directories like:
- page_archives/2017-06-08
- page_archives/2017-06-09
and so on. I'm currently archiving about 10 gigabytes per day spread across 200k to 240k individual files. There is a backing database table that stores per object metadata so I can fetch back the information that I need. My long term plan has always been to store this information in S3 and looking at the data last night I had the epiphany I need to compress it – or do it?
Here's what I know:
- 200K files per day
- 10 gigs per day, every day so 300 gigs per month
- 6,000,000 put requests per month; dramatically lower read volume
The data I'm archiving are simple html files and a quick test with gzip shows dramatic compression:
206729 Jun 9 06:41 ad69734d630423333479b0a954ab52baf056c16d.html
24881 Jun 9 06:41 ad69734d630423333479b0a954ab52baf056c16d.html.gz
Yep - that's a 10x difference in size, 200K down to 24K. Surely it must be worth it to compress, right? Normally this is exactly where I'd be rolling up my sleeves and implementing but, happily something wasn't sitting right with me so I turned to the much maligned AWS calculator. I ran two calculations, each of which is screen shotted below:
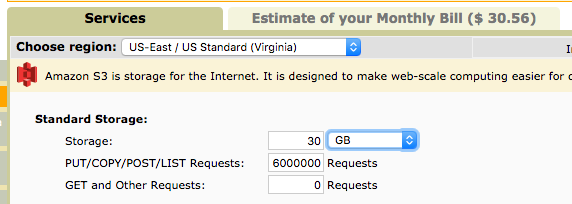
No Compression
Compression
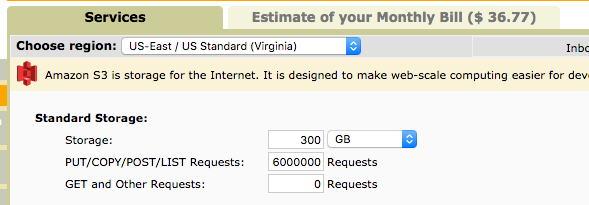
Yep. That's right – the grand price difference of a 10 fold difference in size is all of $6 or 16.67%. Now a 16 % cost savings shouldn't be dismissed but at the current scale I'm running it, it is a rounding error and can be ignored.
The Moral of the Story
Everyone always says that you can never understand your bottlenecks without benchmarking and that has always proven to be true for me. I think guessing about cost structures in today's cloud follows a similar rule – benchmark first and then implement, what you think may be pricey may actually not be.