AWS Tutorial 10 - Diagnosing SSH Failures or When Ping Works But SSH Fails
I just had the issue where a Capistrano deploy onto our AWS cluster of boxes failed. This let me into the following process of debugging:
- Can I ping each box? Yes!
-
Can I ssh into each box? No! The box we name ficrawler2 was unable to be ssh'd into and gave this error:
ssh ficrawler2 ssh_exchange_identification: read: Operation timed out
My next action was to look at the instance in the web console and discover that it was actually reachable from the perspective of:
- System reachability check passed
- Instance reachability check passed
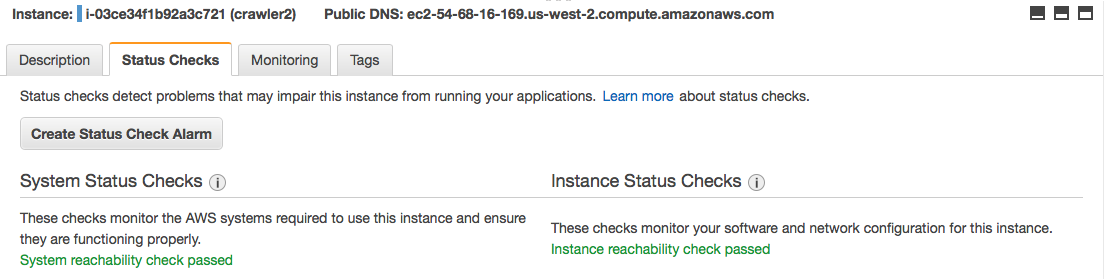
This makes me think that SSH itself went down but external network metrics like ping remained up. Next step up is to reboot the box. And I did that and the problem persisted. This led me to thinking that there's a lower level problem here, possibly network layer?
Now from my ssh config tutorial you might know that my ssh config file defined ficrawler2. Here are the particulars:
Host ficrawler2 Hostname ec2-54-68-16-169.us-west-2.compute.amazonaws.com User ubuntu IdentityFile /Users/sjohnson/.ssh/fi_nav_sitecrawl.pem Port 22
So this lets us construct a debuggable ssh connect line:
ssh -i "/Users/sjohnson/.ssh/fi_nav_sitecrawl.pem" ubuntu@54.68.16.169 -vv
The result of the ssh -i line above will be a very long string of ssh commands showing what happened.
Unfortunately by the time I did the research to figure this out and setup this blog post, ssh returned and I'm left scratching my head more than a bit.
Lessons Learned
Here's what we now know:
- A box can be ping'able but not ssh'able
- Next time I may want to not reboot so quickly
- A reboot doesn't necessarily clear it up so the underlying box might actually have been fine
- I need to write the ssh test line faster next time
- It is very unclear how AWS cloud watch can be used to test for a box that is unable to be ssh'd into; that may not be viable (monitoring it could actually be construed as an attack)
Update 1
This has continued to happen and I was able to capture the diagnostic output:
ssh -i "/Users/sjohnson/.ssh/fi_nav_sitecrawl.pem" ubuntu@52.89.105.4 -vv
OpenSSH_6.9p1, LibreSSL 2.1.8
debug1: Reading configuration data /Users/sjohnson/.ssh/config
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 20: Applying options for *
debug1: /etc/ssh/ssh_config line 102: Applying options for *
debug2: ssh_connect: needpriv 0
debug1: Connecting to 52.89.105.4 [52.89.105.4] port 22.
debug1: Connection established.
debug1: key_load_public: No such file or directory
debug1: identity file /Users/sjohnson/.ssh/fi_nav_sitecrawl.pem type -1
debug1: key_load_public: No such file or directory
debug1: identity file /Users/sjohnson/.ssh/fi_nav_sitecrawl.pem-cert type -1
debug1: Enabling compatibility mode for protocol 2.0
debug1: Local version string SSH-2.0-OpenSSH_6.9
ssh_exchange_identification: read: Connection reset by peer
Update 2 - The Response from AWS Tech Support
Good Day,
I understand that you are unable to access some of your instances via ssh at random times. Please correct me if I miss understood.
Are you still experiencing the issue, or was the problem resolved after the reboot? I've noticed that all the instances with the name "crawler" was started around the same time (2016-10-03 14:25:38 UTC ). Did you have the same issue on all of these instances?
Normally when an instance is inaccessible via ssh, it could indicate a network error or high CPU utilization on the instance. I had a look at the instance metrics for CPU and networking, and all seems to be within acceptable ranges. I can confirm that there are no failures or events on the underlying hardware.
I understand that you want to investigate the cause of the issue and prevent it from happening again.
The best place to start with troubleshooting is to have a look at the OS log files. For Ubuntu; you can have a look in the /var/log/syslog file, or the output of the dmesg command. Please have a look for any warnings or error messages around the time that you've experienced the issues.
What error message did you get when you tried to ssh to the instances?
Were you able to consume any other service that was running on these instances? For example could you still access the web page or MySQL?
Did you try to access the instances from the internet or from another instance on the same network range?
Can you perform a traceroute to the instances now, and again when you are seeing the issue? This can help identify network issues.
I also see that your security group, sg-DFDDFD, allows ssh access from the world (0.0.0.0/0). Leaving port 22 open to the world is a security risk as it leaves your instances vulnerable for attack. I would recommend that you remove this inbound rule and only allow ssh access from trusted IP addresses.
If you want to eliminate manual intervention when an instance fails, you can have a look at Auto Scaling. This will automatically start new instances or stop faulty ones when health checks fails. You can reference the below links for more information about Auto Scaling if you're interested.
https://aws.amazon.com/autoscaling/ http://docs.aws.amazon.com/autoscaling/latest/userguide/GettingStartedTutorial.html
Best regards,
Stefan F. Amazon Web Services We value your feedback. Please rate my response using the link below.