AWS Tutorial 18 - When You've Lost Your Web Server, How to Find an AWS Resource
I find myself, at the time of this writing, in the middle of an embarrassing situtation for a web professional. You see, the situation is this:
- I wrote a new feature
- I deployed my new feature
- I refreshed my page
- My feature isn't there
Great Googly Moogly! I've lost my web server!
Let me explain one of the things about cloud hosting that's disconcerting. When you first move to the cloud, your impulse is to organize your computing resources the way you used to. So if you used to have say 3 clusters of powerful machines, that's what you do. Then you realize just how mind blowingly powerful a platform like AWS actually is and you start to think about Single Purpose Servers. A single purpose server is just what it sounds like – it does one thing. And that's fantastic because it makes trouble shooting so much easier. When a server does only one thing, well, its easy to know if its broken. And that's great but do you know what the side effect of that is? You don't have a handful of servers anymore, you have a lot. Me? I've got over 20 right now. And somewhere in there is my web server. But I can't find it. In this tutorial we're going to quickly and easily figure this out.
Start with a Hypothesis
As normal we're going to start with a theory - that is one of these three boxes: fimariadb, ficrawler1, ficrawler2. So our diagnostic dance, crude tho it may be, is:
- ssh into one of the boxes
- sudo su -
- apache2ctl stop
- reload the page
If the page comes up, well, we know it wasn't that one box. So you then lather, rinse, repeat for each of the other 2 boxes. And, at the end, we're going to find out that it was none of these.
You might be saying "Hey wait a minute – why would a web front end be on a box that does crawling?" Well I'm still feeling all this out and I initially went for the old model where every box could do everything. And that was a bad decision but I still have to live it for at least a little while longer.
Formulate a New Hypothesis - Let's Use Ping!
Since our first plan failed, we need a new plan. The program ping is a basic IP networking tool which lets us send a packet to a destination and if it answers, well, that means its alive.
ping banks.finavd.com
PING web-1166333941.us-west-2.elb.amazonaws.com (52.41.182.115): 56 data bytes
64 bytes from 52.41.182.115: icmp_seq=0 ttl=47 time=67.589 ms
64 bytes from 52.41.182.115: icmp_seq=1 ttl=47 time=67.301 ms
Ah ha! We have an ip address of 52.41.182.115. I know! I know! I know! I'll just search for that ip address on EC2 dashboard. And it will fail. Now the smart kids in the back are already chuckling to themselves and they know the answer.
Hypothesis 3: ELB Is Being Used
If you look at the url that responded, NOT the ip address, the answer is revealed:
web-1166333941.us-west-2.elb.amazonaws.com
You see the text string ".elb."? That means that a piece of software called an Elastic Load Balancer is sitting in front of the http request and distributing the load out to one or more EC2 instances. If you've ever used HAProxy, well, ELB is that only far, far better. Let's goto the AWS Console and select the Load Balancers option from the choices on the left:
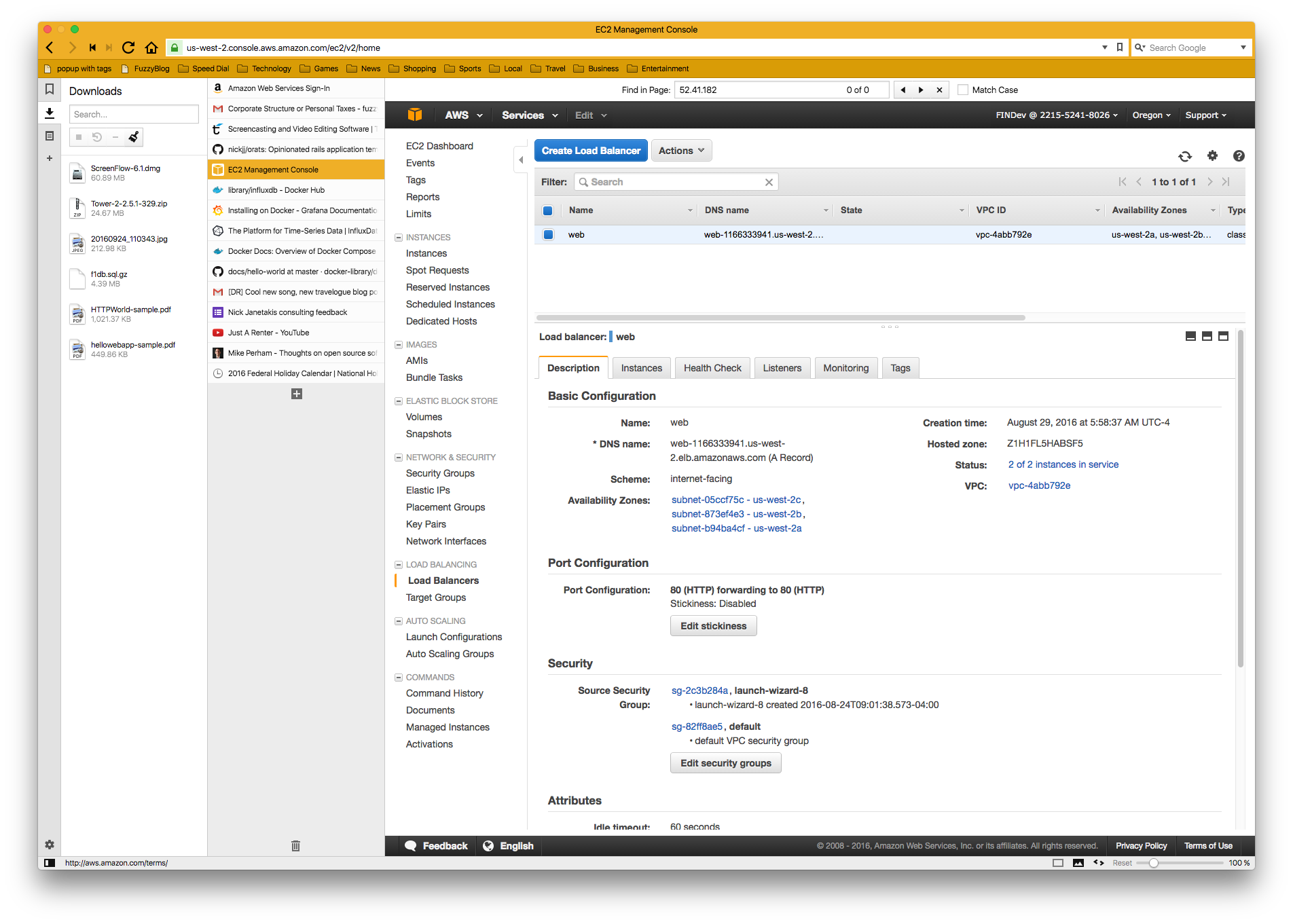
Here we'll see an overview of all of our load balancers and their basic settings.
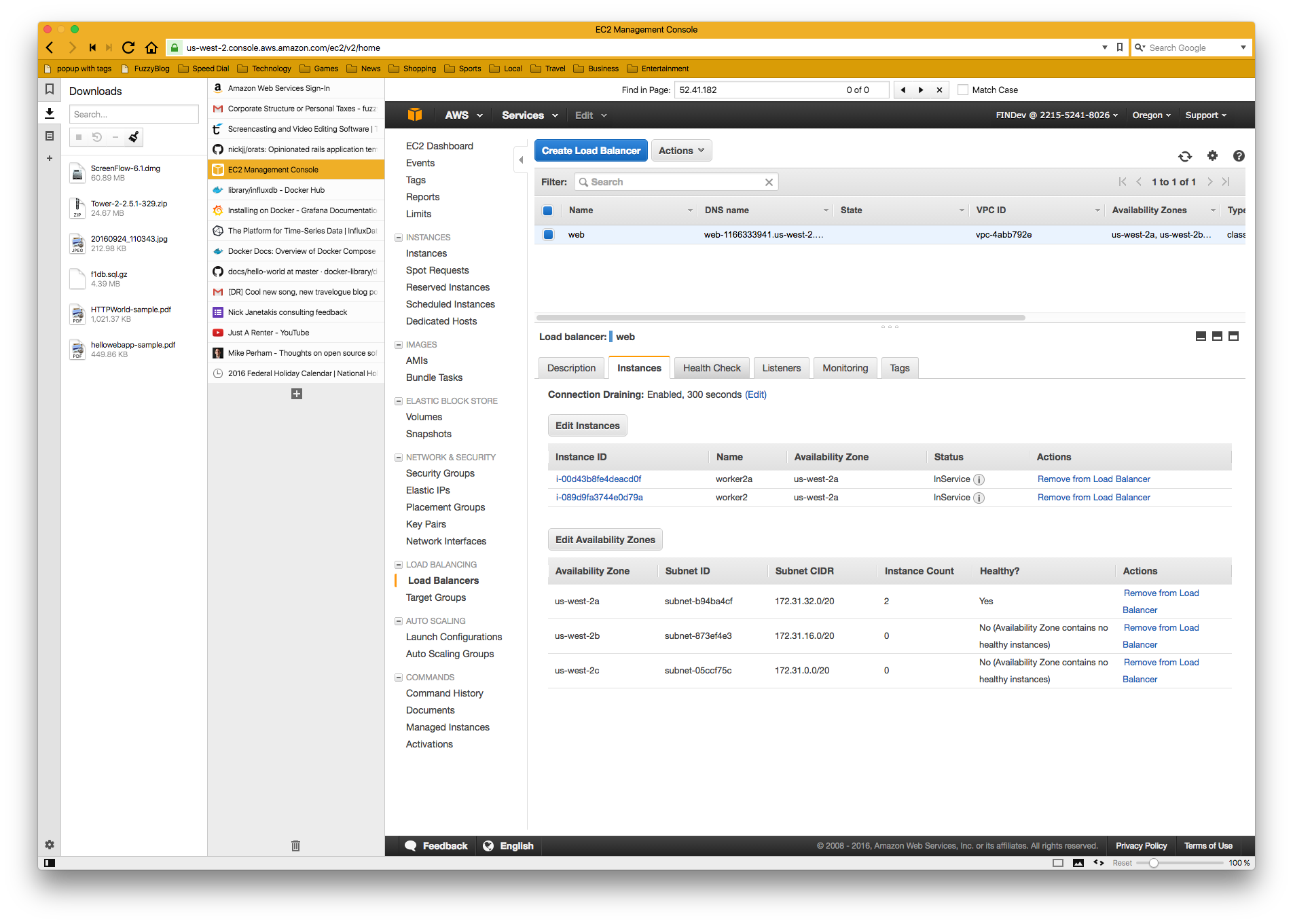
Clicking the instances tab shows us where the HTTP request is being sent. We can now goto the ec2 console and figure out what we need. If you put the machine names into your SSH Config as I recommended then you might not even need to goto the console. In my case I just needed to know the names worker2 and worker2a and I know that they're in my ssh config file and I can just add those boxes to my Capistrano deploy process. And the "bug" is fixed!
Conclusion and Suggestion
I know that it must seem like I'm a bit of a buffoon – how can you lost a web server after all? Well, things do happen when you move fast. You start with one plan and then it doesn't work and before you know it you have something working but its not where you originally planned. And you mean to fix it but you get busy and then the next crisis happens and you're not even in the same head space any more. And by the time you return to it over 10 days have passed.
Here are some suggestions for setting up your AWS architecture to avoid this kind of silliness:
- Name things well.
- Name things logically.
- Use the key value options when you set up your EC2 servers. For example, having keys for both name and role might have helped.
- Remember that there are often abstractions around everything.
- Try and use single purpose servers from the start. Yes the number of discrete servers increases complexity but their very single purpose nature makes debugging vastly easier. And keep in mind that Amazon offers free servers. Even a t2.micro free instance has 1 gig of ram and 8 gigs of storage. I know that sounds funny but travel back in your head 5 years and that's a beefy server and its FREE. If you're just running something small, say Redis, Memcached, sendmail, etc that might be enough for a lot of applications.
Posted In: #aws